Az SQL Server 2000 OLAP szerverének szolgáltatásai
Az OLAP-ról általában
Napjaink vállalatai eljutottak arra a szintre, ahol a hagyományos technológiák kínálta elemzési lehetőségek elégtelennek bizonyultak a növekvő verseny mellett kialakult új piaci feltételek között. Évről évre növekvő mennyiségű és egyre részletesebb alapadatokkal állunk szemben, így az információ kinyerésének sebessége folyamatosan csökken. Ennek következtében diverzifikálódott az adatbázis kezelők piaca. Megjelent egy új adatmodell, amely már képes volt a felhasználók (döntéshozók) igényét megfelelő gyorsasággal és könnyű kezelhetőséggel kielégíteni. Ezt az új adatmodellt az OLAP betűszóval illették, az On-Line Analytical Processing kifejezés rövidítéseként. Az adatmodell és annak tárolási stratégiája azonban nem támogatja a napi működés közben keletkezett információk tárolását és feldolgozását, így az továbbra is a hagyományos relációs adatbázis kezelők (operatív, működtető rendszerek) feladata maradt, és az OLAP-ot pedig ráültették ezekre a rendszerekre. Tehát az OLAP adatbázisok nem helyettesítik, nem is helyettesíthetik a működtető rendszereket, illetve azok faladatait, csak mintegy kiegészítőjükként működhetnek.
Így általánosan elmondható, hogy az OLAP rendszerek a működtető rendszerek adatiból táplálkoznak, periódikusan áttöltve azok adatinak egy részhalmazát.
Az OLAP követelményei
- Adatbázisa csak az elemzéshez szükséges adatokat tartalmazza
- Többdimenziós nézet, amely kielégíti az elemzők igényeit
- Adatbázisa felösszegzett és elemi információkat egyaránt tartalmaz
- Az adatbázisban tárolt információ lekérdezésének sebessége nagyságrendekkel nagyobb, mint a hagyományos módon tárolt adatbázisok lekérdezésének sebessége
- felhasználó barát, a kliens oldali lekérdezés összeállítása drag and drop módszerrel történik.
Azokat a rendszereket, amelyek kielégítik a fent vázolt követelményeket, összefoglaló néven OLAP rendszereknek nevezzük. Az OLAP szinonimáiként gyakran használatosak a MIS (Management Information System) ennek magyar megfelelője a VIR vagy Vezetői Információs Rendszerek, a DSS (Decision Support Systems), a BI (Business Intelligence), valamint az EIS (Excecutive Information Systems) kifejezések.
Data Transformation Services (DTS)
A működtető rendszerek adatainak azon részét, amely az elemzéshez szükséges át kell emelnünk az OLAP adatbázisába. Ez azt jelenti, hogy a vállalati adatoknak lesz olyan részhalmaza, amely duplikáltan lesz tárolva, elérhető OLAP-ból illetve az alaprendszerből is. Az SQL Server 2000 a relációs és többdimenziós tároló motorok mellett tartalmaz, egy adatbetöltési funkciót ellátó programot is, amely grafikus programozási felület segítségével tölti be a transzformált forrás adatokat a cél adatbázisba.
AZ OLAP Adatbázisa
Az adatkockák témaorientáltan tartalmazzák az elemzéshez szükséges adatokat, melyek adatbázissá szerveződnek. (Hasonlóan a relációs adatbázisoknál használt táblákhoz). Bár kockákról beszélünk, melyek 3 dimenziós testek egy MS OLAP adatkockának akár 128 dimenziója is lehet. A dimenziók segítségével határozhatjuk meg az adatkocka egy pontjának helyét és tartalmát, mint ahogy egy n dimenziós tér egy pontjának meghatározásához n darab koordináta szükséges. Ezeket a koordinátákat nevezzük a dimenziók tagjainak vagy elemeinek. Amikor tehát lekérdezünk egy adatkockában tárolt adatot, az adatkocka összes dimenziójának meghatározzuk egy-egy elemét és az ezen koordináták által meghatározott síkot megjelenítjük a képernyőn. (Vesszük az n dimenziós kocka egy kétdimenziós szeletét) Tegyük fel, hogy adott egy Idő, Cikk, Vevő dimenziókkal rendelkező 3 dimenziós adatkockánk, amely pontjai árbevétel adatokat tartalmaznak. (kinek, mikor, mit és mennyiért értékesítettünk). Annak meghatározásához tehát, hogy egy konkrét vevő egy konkrét cikkből egy adott időszak alatt mennyit vásárolt, a vevő, cikk, idő dimenziók egy-egy elemének kijelölésével juthatunk. A dimenziók tagjait hierarchiákba szervezhetjük, azaz a dimenzió elemeit összegző és részletező csoportokba sorolhatjuk. (Pl.: év, negyedév, hónap, nap). Mivel az összegző elemek is a dimenzió tagjai, ezért az összegző elemek kijelölésével a fenti példa alapján meghatározható az árbevétel értékének éves összege is. (Miután összegző elemet vettünk fel a dimenzióba, az ahhoz tartozó értéket kiszámítottuk a gyerekek értékének összegeként és letároltuk az adatkocka megfelelő pontjaiba) Az OLAP adatbázisa tehát úgy van megszerkesztve, hogy az említett koordinátákhoz tartozó adatokat minél gyorsabban megtalálja.
MDX
Az MDX (Multidimensional Expressions) a MS OLAP adatbázisok lekérdező nyelve, amely egyúttal az OLE DB for OLAP szabvány része. Ezért az MDX más gyártók által forgalmazott OLAP adatbázisok lekérdezésére is használható, ha azok csatlakoztak a szabványhoz. (pl.: TM1, SAS,...) Az MDX lekérdezés kicsit hasonlít az SQL SELECT–hez. Például a
SELECT
Time.members ON COLUMNS,
Cikk.members ON ROWS
FROM Ertekesites
WHERE Vevo.Total
lekérdezés eredményéül az Ertekesites adatkocka olyan kétdimenziós szeletét kapjuk, amelynek oszlopán az összes időpont, során a cikk dimenzió összes eleme található. A where feltétellel határozzuk meg az adatkocka kétdimenziós szeletének kijelöléséhez szükséges lapozó dimenziók elemeit (a hiányzó koordinátákat).
Az adatkocka koordinátáira a dimenzió elemek egyedi nevével (Unique name) hivatkozunk. Ezt az egyedi nevet az Analysis Services belsőleg határozza meg az adott elem kódja (vagy megnevezése) és hierarchiabeli helye szerint.
Adatkockák
Az adatkockák olyan adatbázis objektumok, amelyek az elemzéshez szükséges adatokat úgy tárolják, hogy azok egy tetszőleges szeletének lekérdezése a leggyorsabban megvalósuljon. Legtöbbször valamilyen OLTP rendszer, elemzéshez szükséges adatait és azok összesítését tartalmazza. Lekérdezésük során, a kliens oldalon – rendszerint egérkattintásokkal – jelöljük ki a koordinátákat, amely alapján az adatbázis szerver visszaadja a lekérdezés eredményeként meghatározott sík adatait. OLAP adatkockák tárolhatóak relációs vagy többdimenziós adatbázisokban egyaránt. Mielőtt tehát létrehozunk egy adatkockát meg kell határoznunk annak tárolási módját.
MOLAP, ROLAP, HOLAP…
Az Analysis Services képes az adatkockákat három különböző stratégia szerint tárolni. (Csak többdimenziós, csak relációs és egyik részét a többdimenziós másik részét a relációs adatbázisokban tárolva) Arra a kérdésre, hogy mikor, melyik tárolási stratégiát alkalmazzuk, nincs egyértelműen meghatározható szabály, de ökölszabályként használható, hogy ha a lekérdezés sebességének maximalizálása a cél, akkor tároljuk adatainkat a többdimenziós oldalon, ha pedig a tárkapacitás minimalizálása a cél, akkor tároljuk adatainkat a relációs oldalon.
|
MOLAP |
ROLAP |
HOLAP |
|
Adatok tárolása többdimenziós adatbázisban
|
Adatok tárolása relációs oldalon |
összegzett adatok tárolása a többdimenziós, elemi adatok tárolása relációs oldalon |
|
Leggyorsabb Lekérdezés |
Legkisebb tárkapacitás |
A kettő ötvözése |
A szűk keresztmetszettől függően tehát szabadon választhatunk a tárolási módok között. Sőt, lehetőségünk van akár egy adatkockán belül több tárolási mód választására is. Például 5 évvel ezelőtti ritkán használt adatainkat tárolhatjuk a tárkapacitás szempontjából leghatékonyabb ROLAP partíción, míg az 5 éven belüli adatokat a lekérdezés sebességére optimalizált MOLAP partíción. Természetesen a felhasználó nem látja, hogy az adatkocka egyes részei külön partíción vannak tárolva, csak legfeljebb a lekérdezés sebességéből sejtheti, hogy éppen egy ROLAP partíciót kérdez le. A partíciókat sem szükséges egy szerveren tárolni, hanem megoldható, hogy egy központi Analysis szerverről regisztrálva a partíciókat külön-külön, több szerveren helyezzük el.

Az adatkockák particionálása természetesen megfordítható folyamat, azaz a partíciókat bármikor összevonhatjuk.
Offline OLAP
Az adatkockák adatbázis szerveren történő tárolása helyett használhatunk úgynevezett kockafájlokat (*.cub). Ezek a hordozható adatfájlok egy létező adatkockából akár az Excel 2000 segítségével is előállíthatóak, melyek szerveren vagy asztali gépeken tárolva is lekérdezhetőek. Így kockafájlok segítségével a vezetők munkahelyüktől távol, a központi szerver elérése nélkül elemezhetik a számukra fontos információkat.
Virtuális adatkockák
A virtuális adatkocka több, létező adatkockából előállított logikai adatkocka, amely adatokat nem, csak az adatok címeit tartalmazza. A virtuális adatkockát úgy állítjuk elő, hogy a forrás adatkockák közös részhalmazából kiválasztjuk a szükséges dimenziókat és azok elemeit. (Hasonlóan a view-hoz). Miután elkészült a virtuális adatkocka, a felhasználó ugyanúgy használhatja azt, mint egy tárolt adatkockát. Gyakran használunk virtuális adatkockát több kocka adatainak számszerű összehasonlítására, de arra is, hogy bizonyos felhasználók elől elrejtsük a nem rá tartozó adatokat. (Egyetlenegy adatkockából több virtuális kocka is képezhető)
Dimenziók
A dimenziók olyan minőségi, területi, stb. ismérvek, amelyek leírják az adatkocka adatát. Annyiféle szempont szerint vizsgálhatjuk adatainkat, ahány dimenziót az adatkockához rendeltünk. Az adatkocka dimenzióinak számát a kocka létrehozásakor mi határozzuk meg, figyelembe véve a felhasználók igényeit és a rendelkezésre álló adatok részletezettségét. A dimenziók meghatározásánál mindenképpen szem előtt kell tartanunk, hogy a dimenziók elemeinek ne álljon elő olyan kombinációja, melynek az elemzési terület szempontjából nincs értelme. (Az OLAP adatkockáknak nincs kitüntetett sor vagy oszlop dimenziója, azaz ez a két dimenzió tetszőlegesen választható ki az adatkocka összes dimenziója közül.)
ROLAP dimenziók
Az Analysis Services újdonsága, hogy dimenziót tárolhatunk a többdimenziós adatbázis helyett a relációs adatbázisban is. A dimenzió relációs oldalú tárolásával elérhető, hogy elemeinek száma meghaladja a tízmilliót, és a rájuk épített hierarchiák akár futás közben is változtathatóak legyenek. A ROLAP dimenziók robosztusságát használhatjuk ki „click-stream” elemzések készítésekor, így például amikor a weblapunkra látogatók adatait és szokásait idősorosan és összegezve elemezzük.
Hierarchiák
A hierarchiák a dimenzió elemek közötti kapcsolatot írják le. Ezek rendszerint fa-struktúrájúak. A hierarchia mentén a gyökérponttól a levélpont felé haladva egyre részletesebb adatokhoz jutunk. Egy dimenzió adataiból akár több hierarchiát is építhetünk, például az idő dimenzión létrehozhatjuk az év, negyedév, hónap, nap és az év, hét, nap bontású hierarchiát is.
Kiegyensúlyozott és kiegyensúlyozatlan hierarchiák
Egy hierarchia kiegyensúlyozott, ha a gyökérponttól egy tetszőleges levélpontig tartó útvonalon a csomópontok száma állandó. Minden más esetben a hierarchia kiegyensúlyozatlan.
Szakadozott hierarchiák
Egy hierarchiát szakadozottnak nevezünk, ha legalább egy elemének logikailag legközelebbi szülője nem közvetlenül az elem fölött található szinten helyezkedik el. Például az ország-megye-város hierarchiában Budapest szülője nem a megye, hanem az ország szinten helyezkedik el. Egy hierarchia csak akkor lehet kiegyensúlyozatlan és szakadozott, ha az szülő-gyerek típusú.

Szülő-gyerek hierarchiák
A szülő-gyerek hierarchiák forrástáblája két oszlopot tartalmaz, amelyek együttesen írják le a dimenzió elemei közti kapcsolatot. A gyerekkód oszlop azonosítja a dimenzió összes elemét, míg a szülőkód oszlop az összes elem szülőjét.
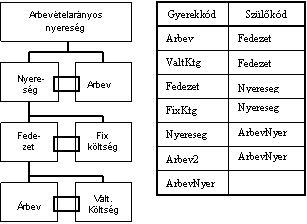
A szülő-gyerek dimenzió összegző szinten elhelyezkedő eleméhez is tartozhat érték a vele dimenzionált adatkocka forrástáblájában. Ez felösszegzések során problémához vezethet, hiszen definíció szerint a szülő értékét a gyerekek értékéből számítjuk. Esetünkben azonban az adott szülőhöz tartozik egy olyan érték, amely a gyerekek adataitól független. A probléma megoldására felveszünk az adott szülő alá egy új gyerek elemet, amelyhez hozzárendeljük forrástáblában hozzá tartozó értéket. Ezt a speciális elemet data member-nek nevezzük, és a hozzá tartozó adatot kétféleképpen jeleníthetjük meg:
- felösszegzés során nem vesszük figyelembe, hogy a szülő elemhez tartozik érték a forrástáblában
- a szülő elem gyerekei között szerepeltetjük a data membert, amelyet a felösszegzések során ugyanúgy figyelembe veszünk, mint egy közönséges gyereket (Pl.: egy vezető teljesítménye megegyezik önmaga és beosztottai által végzett teljesítmények összegével.)
A data member egy belsőleg létrehozott és karbantartott dimenzió elem
Gyakran változó dimenziók (changing dimensions)
Gyakran változónak nevezünk egy dimenziót, ha annak szerkezete (tagjainak relatív helyzete a hierarchiában) a rendszeres adatfeltöltések során gyakran változik. Ez egy logikai tulajdonság, amely minden dimenzió típusnál (kiegyensúlyozott, szakadozott, ...) beállítható. Ha egy dimenziót gyakran változóvá teszünk, akkor strukturális változás esetén elég inkrementálisan felösszegezni a vele dimenzionált adatkockákat. A lehetőség kihasználásával gyorsabbá tehetjük az adatkockák felösszegzését, de ez sajnos a lekérdezés sebességének csökkenését eredményezi. Így ha egy dimenzió szerkezete ritkán változik, akkor nem célszerű beállítani a fent említett tulajdonságot. A virtuális, ROLAP, és Szülő-Gyerek dimenziók mindig gyakran változó dimenziók.
Dimenziók szerkezetének futás közbeni megváltoztatása
Az OLAP-pal szemben támasztott követelmények között gyakran szerepel olyan igény, hogy az eszköz ne csak elemzésre, hanem modellezésre is alkalmas legyen. A modellezés során egy speciális, kliens oldalról szerkeszthető Szülő-gyerek hierarchiát hozunk létre, amelyek elemei mutatószámok. Ezek a szerkeszthető (Write-enabled) dimenziók lehetőséget teremtenek a felhasználóknak, hogy futás közben szerkesszék meg az említett mutatószámokat, illetve meghatározzák hierarchiabeli helyzetüket. Természetesen lehetőségük van mutatószámok felvételére, törlésére, tulajdonságaik megváltoztatására is. A szerkeszthető dimenziók kitágítják az elemzés határait, hiszen velük a felhasználók komplex mutatószámrendszereket, testre szabott hierarchiákat alakíthatnak ki. Mivel az Analysis Services bármely felhasználó által eszközölt változást ugyanabba a táblába (a dimenzió forrástáblájába) írja vissza, ezért egy dimenzió szerkeszthetővé tétele előtt pontosan meg kell határozni azon felhasználók körét, akik a dimenzió szerkezetét megváltoztathatják.
Számított mezők (Calculated members)
A számított mezők olyan logikai dimenzió elemek, amelyek értékei más elemekből MDX képletek segítségével származtathatóak. (Pl. átlagár). A számított mezők az eredményt nem, csak annak a kiszámításához szükséges képleteket tárolják, és ha szükséges az eredményt a lekérdezés során kiszámítják. A számított mezők hozzáadásával lehetőségünk van az adatkocka információ szolgáltató képességét úgy növelni, hogy a kocka mérete ne növekedjen. Ezáltal csak származtatott információt nyerhetünk, de a több mint száz előre definiált függvény és az általunk regisztrálható függvények (UDF) segítségével a komplex elemzések könnyebben elkészíthetők.
Dimenzió elemek tulajdonságai (Member Properties)
A dimenzió elemek tulajdonságai olyan plusz információt hordoznak a dimenzió elemeiről, amelyek csoportosítási szempontnak nem minősülnek és az elemzés szempontjából e jellemzők összegzése nem ad új információt, de mint minőségi ismérv fontos tulajdonság. Ilyen lehet például a termék csomagolása, térfogata, színe. Lekérdezés során lehetőségünk van a dimenzió elemek közül azok kiválasztására, amelyek megfelelnek egy adott tulajdonságnak. Egy másik alkalmazási terület lehet a többnyelvű adatbázisok létrehozása. A dimenzió elemek tulajdonságai között letárolva azok idegen nyelvű megnevezéseit, az Analysis Services automatikusan a kliens oldali regionális beállításinak megfelelő nyelvű megnevezéseket adja vissza.
Felösszegzés
Ahogy azt már korábban említettük az előre kiszámított, felösszegzett adatok nagymértékben növelik az OLAP rendszerek lekérdezési sebességét. A periódikusan ismétlődő adatbetöltés és felösszegzés során azonban az OLAP adatbázisok mérete exponenciálisan növekszik. Az Analysis Services segítségével azonban szabályozni tudjuk a felösszegzett adatok letárolását. Meghatározhatunk azt az arányt, hogy az aggregált adatok hány százaléka legyen letárolva, és hány százalékát számítsa ki az Analysis Services a lekérdezések alkalmával. A tárolt adatok térbeli elhelyezkedéséről azonban az Analysis Services matematikai algoritmusa dönt. Például egy 40%-os aggregáció tárolás esetén az Analysis Services határozza meg azt, hogy a 40 százaléknyi aggregált adat a 100 százaléknyi aggregációs lehetőség közül hol álljon elő. Ez az algoritmus jó közelítéssel optimális megoldást ad. Az adminisztrátoroknak lehetőségük van a rendszer további finomhangolására, mivel az Analysis Services tárolja azokat a lekérdezéseket, amelyeket a felhasználók futtattak a szerveren. Ezen információk felhasználásával az aggregációk térbeli elhelyezése tovább finomítható.
Az OLAP és OLTP rendszerek közti egyik különbség az, hogy míg az OLTP rendszerekbe rövid, addig az OLAP rendszerekbe hosszabb ideig tart az adatok betöltése és felösszegzése. Nagyon nagy kockák esetében ez akár órákig is eltarthat. Ezért szintén nagyon fontos kérdés az adatok felösszegzésének sebessége. Az Analysis Services három fajta felösszegzési típust támogat. Full process felösszegzési típus esetén törli az adatkocka struktúráját és tartalmát majd újra létrehozva, felösszegzi azt. Ezt az eljárás legtöbbször csak a fejlesztés/tesztelés periódusában használjuk, a napi működés esetén az incremental Update és refresh data felösszegzési típusok közül választhatunk. E két utóbbi típus nem változtatja meg az adatkocka struktúráját csak a benne tárolt adatokat cseréli, vagy új adatokat ad hozzá a meglévő adatokhoz. Incremental UpDate esetén az Analysis Services létrehoz egy particiót amelyen az új adatokat tárolja és a felösszegzés közben az adatkocka és az új adatok partícióit összevonja, adatait összeadja
Amennyiben az üzlet természetéről rendelkezünk információval és meg tudjuk határozni azon dimenziók körét, melyek elemeinek bizonyos kombinációjában soha nem szerepelhet érték, akkor a két dimenzió függőségi kapcsolatát meghatározva (Dependent dimensions) a felösszegzés alatt az Analysis Services figyelmen kívül hagyja az említett kombinációk kiszámítását - ezáltal csökkentve az aggregációk számát és a felösszegzés sebessége tovább gyorsítható.
Az üres cellák tárolása szintén az OLAP adatbázisok méretének exponenciális növekedését okozhatja. A legtöbb gyártó ad valamilyen megoldást a problémára, melyek során például be lehet állítani olyan dimenzió elem kombinációkat, amelyekbe biztos nem kerülhet érték. (Például Miskolcon nem értékesítünk gumimatracot), vagy az adatbázist úgy kell megszervezni, hogy az üres cellák kerüljenek egymás mellé, amit aztán a rendszer, ha egy lapnyi üres cellát talál, nem tárol le. Ezzel szemben az Analysis Services egyáltalán nem tárol üres cellákat.
Real-Time OLAP
Az OLAP az On-Line Analytical Processing szavak kezdőbetűjének összetételéből származik, és nem on-line adatelérést jelent a működtető rendszerek adataihoz. Az OLAP adatbázisa és a működtető rendszerek közötti kapcsolat az OLAP felé egyirányú, és csak periódikusan, a betöltések alkalmával jön létre. A gyakorlati életben viszont előfordul, hogy az OLAP adatkockákban látni szeretnénk a két adatbetöltés közötti változásokat is, azaz az élő adatokat. A Real-time OLAP az Analysis Services olyan szolgáltatása, amely lehetővé teszi, hogy az adatkocka forrástáblájának megváltozásával összhangban megváltozzanak a Real-time adatkockában tárolt adatok is. (A Real-time kocka szinkronizálva van a működtető rendszerekkel) A Real-time adatkocka nem más, mint egy speciális, ROLAP partíción tárolt adatkocka 0%-os felösszegzettséggel. Amennyiben a dimenzió szerkezete is real-time változik, úgy ROLAP dimenziót használva, annak hierarchiáját is szinkronizálhatjuk az alaprendszerekhez.
Adatkockák adatainak módosítása
Az Analysis Services lehetőséget teremt a felhasználóknak az adatkockák adatinak módosítására. Az adatokat módosíthatjuk elemi szinten (a hierarchia legalsó szintjén) és valamelyik összegző szinten. Vizsgáljuk meg először az egyszerűbb esetet, amikor csak az elemi szintű adatokat módosítjuk. (Csak olyan adatkocka módosítható, amelynek minden hierarchiabeli szülője a gyerekek összegeként áll elő.) Az Analysis Services a módosításokat sem az adatkockába, sem annak forrástáblájába nem írja vissza, hanem létrehoz relációs oldalon egy külön writeback táblát, amelyben a módosított adatok, és az alapadatok különbségét tárolja. Például, ha a felhasználó egy cella értékét 90-ről 100-ra növeli, akkor a writeback táblában az Analysis Services letárol +10 értéket a módosítás időpontjával és a módosító felhasználó nevével. Később, az adatkocka lekérdezésekor az Analysis Services a módosított cellához és annak összes szülő értékéhez hozzáadja a writeback tábla kapcsolódó értékét. (A módosítás az adatkocka adatait nem érintette) A módosított adatokat visszaírhatjuk a kockába, ha a writeback tábla adatait partícióvá konvertáljuk, majd az alapadatokat és a writeback adatokat tartalmazó partíciókat összevonjuk. (Hasonló a folyamat játszódik le Incremental UpDate esetén is).
Az adatok összegző szinten történő módosítása esetén a módosított értéket szét kell osztani (allokálni) az elemi szinten elhelyezkedő elemekre, majd az allokált adatok writeback táblába írásával folytatódik a folyamat a fent leírtak szerint. Az allokáció végrehajtását az Analysis Services a következő négy eljárással támogatja
|
Allokációs módszerek |
Leírás |
|
Egyenlő allokáció |
Elemi cellák értéke = |
|
Módosított érték / |
|
|
utolsó leszármazottak száma |
|
|
Egyenlő növekmény |
Elemi cellák értéke = |
|
Elemi cellák értéke + |
|
|
(Módosított érték - eredeti érték) / |
|
|
utolsó leszármazottak száma |
|
|
Súlyozott allokáció |
Elemi cellák értéke = |
|
Módosított érték * súlyozó tényező |
|
|
Súlyozott növekmény |
Elemi cellák értéke = |
|
Elemi cellák értéke + |
|
|
(Módosított érték - eredeti érték) * |
|
|
súlyozó tényező |
A súlyozó tényezők rendszerint 0 és 1 közé esnek és összegük 1-gyel egyenlő. A súlyozó tényező meg nem határozása esetén az Analysis Services az elemi cella és a módosított cella eredeti értékének arányával számol.
Egyedi felösszegzési lehetőségek
Az Analysis Services az adatkockákat csak saját felösszegzési eljárásai szerint tudja felösszegezni. (Sum, Count, min, max, DistincCount) Gyakorlati problémák megoldása során azonban előfordul, hogy a rendszer felösszegzési algoritmusai helyett valamilyen egyedi felösszegzési eljárást kell alkalmaznunk. Az Analysis Services Custom Rollup/member formuláival az ilyen jellegű problémák is megoldhatóak.
Custom Rollup formula
Tegyük fel, hogy zárókészletek változását szeretnénk hetente vizsgálni. Ha napi készletértékeket (Pl.: 5,4,5,6,5) aggregálnánk heti szintre, akkor akkora zárókészlet (25) kapnánk, amely talán sohasem volt raktáron. Ezért a heti készletérték meghatározásához célszerű inkább az átlagos, vagy az utolsó napi készletértéket figyelembe venni. Az Analysis Services nem tartalmaz beépített átlagos vagy „Utolsó gyerek” felösszegzési metódust, ezért ezt nekünk kell megvalósítanunk. A megoldás során tetszőleges hierarchia szintekhez hozzárendelünk egy MDX-ben irt képletet (Pl.: Hét=hét.UtolsóGyerek), amelyet az Analysis Services a felösszegzés során nem vesz figyelembe, hanem az adatkocka lekérdezésekor számítja ki. Amennyiben olyan felösszegzési eljárást szeretnénk használni, amely egy hierarchia szinten nem az összes elemre érvényes, Custom Member Formulát célszerű használnunk.
Custom Member Formula
Hasonlóan működik a custom rollup formulához azzal a különbséggel, hogy nem szinthez, hanem dimenzió elemhez rendel képleteket, melyeket az Analysis Services a dimenzió forrástáblájában tárol. A képlet nem hivatkozhat olyan dimenzió elemre, amelyet nem tartalmaz dimenziótábla (pl.: számított mezők). A Custom member formulát legtöbbször mutatószámrendszerek, gazdasági modellek kialakításakor használjuk.
Számított cellák (Calculated Cells)
Ez az új MDX funkció az Analysis Services olyan lehetősége, amely segítségével több különböző adatkocka adatainak részhalmazát tudjuk egy másik adatkocka azonos részhalmazában megjeleníteni. Ezáltal tovább finomítható az adatbázis szerkezete, több kisebb és tömörebb kockát létrehozva tudunk összetett elemzési igényeket hatékonyan kielégíteni.
A számított cellák lehetőséget teremtenek, hogy a számított mezők, custom rollup/member formulák funkcionalitását alkalmazzuk az adatkocka egy (jellemzően többdimenziós) részhalmazára vagy akár csak egy cellára is. Legtöbbször olyan esetekben használunk számított cellákat, amikor az adatkocka egy részkockájának adatait már más adatkocka tartalmazza. (Így lekérdezés során elég az adatokat onnan átemelni.)
Jogosultság kezelés
Az Analysis Services segítségével kétféle lehetőségünk van a jogosultságok beállítására: Cella szinten vagy dimenzió elem szerint. Mindkét eljárással megoldható egy adott cella adatának elrejtése, de kétféle eredménnyel. Cella szintű jogosultság kezelés esetén a felhasználó láthatja az adatkocka teljes struktúráját, azaz a dimenzió összes elemét, de az adatokat nem, míg dimenzió elemek szerinti jogosultság kezelés esetén sem az adott elemet sem a hozzá tartozó adatot.
Action
Az elemzések során gyakran jutunk abba a helyzetbe, hogy észreveszünk egy kiugró adatot, vagy egy tendenciát, de az okokra az adatkockából már nem kapunk a választ. Ilyenkor rendszerint elkezdünk kutakodni különböző információforrásokban, (Például Word, Excel dokumentumokban, alaprendszerek adatai között) hogy megtaláljuk az okokat. Ezt a keresési folyamatot gyorsítja fel az Analysis Services azáltal, hogy a felhasználói felületről lehetővé teszi a fent említett források felkutatását. A gyorsműveletek segítségével lehetőségünk van arra, hogy paraméterek átadásával (Kocka, dimenziók neve, egy cellát meghatározó dimenzió elemek halmaza, stb.) meghívhassunk valamilyen külső alkalmazást (futtatható állományok, MDX lekérdezések, böngészők). A gyorsműveletek segítségével azonnal reagálni tudunk a környezeti feltételek megváltozására. (megrendelések leadása, felszólítások küldése,...)
Átfúrás (Drillthrough)
A továbbfúrás a gyorsműveletek egy speciális fajtája. Segítségével egy adatkocka cellájának adatait tovább részletezhetjük, azaz meghatározhatjuk, hogy az adott cella értéke mely adatok eredményeképpen állt elő. Továbbfúrás esetén az Analysis Services a forrástáblákon lefuttat egy lekérdezést, amely azokat a rekordokat adja vissza, melyekből az adatkocka adott cellájának értékét az Analysis Services kiszámította.
Kliens alkalmazások
A továbbfúrás, mint több más funkció felhasználói oldal kihasználása, erősen kliensfüggő. Ezeket ugyanis az Analysis Services mint lehetőségeket ajánlja fel, és az alkalmazás fejlesztőktől függ, kik milyen funkciót támogatnak, és azokat hogyan tálalják a felhasználók elé. A Microsoft az Analysis Services-hez nem fejlesztett önálló kliens alkalmazást, hanem az Excel 2000-et tette alkalmassá OLAP adatkockák böngészésre. Természetesen lehet komplett elemző és fejlesztő eszközöket vásárolni kifejezetten MS OLAP technológiára, illetve vannak gyártók, akik saját OLAP elemző eszközüket tették alkalmassá MS OLAP adatbázisok kezelésére. A http://www.microsoft.com/sql/offerings.htm weboldalról ezek letöltethetőek. Létezik azonban magyar nyelvű, Excel 2000-be integrált kliens oldali elemző eszköz is, amelynek béta változatát a Novosys kft. OLAPNaviGo néven forgalmazza. (Letölthető a http://www.novosys.hu/ oldalról.)

Kővári Attila - BI projekt




Új hozzászólás