Magyar adattárházak nyelvi problémái II.: ô õ ő o betűk
Itt a dzsoli dzsóker cikk második része, amely ezúttal az ékezetes betűk felöl közelíti meg a magyar adattárházak nyelvi problémáit. A tanulmány sajnos nem sikerült túl rövidre. Épp ezért ha kevés az ideje, akkor ugorjon nyugodtan a végére, ahol összefoglalom, hogy mire kell odafigyelnie, ha adattárházat épít/építtet.
A múltkori cikkben már elkezdtem foglalkozni a magyar adattárházak nyelvi problémáival és bemutattam, hogy a helytelenül megválasztott nyelvi beállítások (Collation) életre szóló problémát jelenthetnek az üzleti felhasználóknak és fejlesztőknek is. De ma egy másik magyar nyelvi sajátosságról, illetve az abból eredő problémáról fogok írni...
Akik adatokat mozgatnak egyik adatbázisból a másikba azok már biztosan legalább egyszer belefutottak az ékezetes karakterek és a nyelvi beállítások különbözőségéből eredő problémákba. Elég csak arra gondolni, hogy különböző okok miatt az o betűből valahol a betöltési folyamat közben egyszer csak o betű lesz.
Két féle fejlesztőt ismerek: Az egyik besöpri a problémát az asztal alá és vagy az SQL szerverre, vagy az adatbetöltő (ETL) eszközre bízza hogy az mivé alakítja az o betűket.
A másik, aki tudja, hogy ezzel mekkora kárt okoz és maga, szinte karakterről karakterre konvertálja a betűket, nehogy elveszítsen egyetlen ékezetett is.
Kétségtelen – és be is fogom mutatni – hogy az SQL Server képes két eltérő nyelvi beállítású adatbázis között karaktereket konvertálni de minderre csak az ékezetek egy részének elvesztésével képes.
Persze ettől még egy postás be fogja tudni dobni a levelet
- Kővári Attilának és
- Kôvári Attilának és
- Kovári Attilának és
- Kovári Attilának is
de egy adatbányász vagy egy statisztikai algoritmus vagy az adattisztításra használt Fuzzy Lookup task már nem birkózik meg ilyen könnyen a problémával. Ahogy egy mezei group by és egy distinct count lekérdezés sem. (persze képzeletbeli postásunk is bajban lenne, ha egy levelet mondjuk Komlora kéne vinnie, mert nem tudná, hogy Komlo valójában Kömlő-e vagy Komló?)
És valljuk be őszintén. Nem csak azért építünk adattárházat, hogy borítékokat nyomtassunk belőle (bár lehet arra is használni csak arra egy kicsit drága) hanem azért, hogy annak adatait elemzésekre tudjuk használni. Megmondom őszintén, hogy elég pipa lennék, ha méreg drágán vennék egy adattárházat és abban nem lennének ő betűk, mert a fejlesztő nemtörődömségből az SQL serverre bízta a konverziót, ami az o betűből o-t csinál. Mert ez a hiba helyrehozhatatlan és következménye egy életre szóló!
Nos. Mielőtt még belevágnánk e tipikus magyar nyelvi problémát kiküszöbölő megoldás tárgyalásának, essen néhány szó a magáról a nyelvi problémáról.
A számítástechnika hőskorában elegendő volt a karaktereket 1 bájton tárolni, mert abba bőven belefért az angol ABC összes betűje plusz még jó néhány speciális karakter is, mint például a +!/*? jelek. De más nemzetek betűinek már nem jutott hely, így a magyarnak sem. Ergo ki kellett találni valamit.
A megoldást a kódlapok jelentették. Minden nemzet (illetve pontosabban minden nemzet csoport, akik közel azonos karaktereket használnak) kapott egy saját kódlapot, amelyben már helyet kaptak a nemzetek speciális karakterei is, mint például az ékezetes betűk. Így egy nemzeten belül már nem jelentett problémát a helyes karakterek tárolása.
De a nemzetek (nyelvek, kódlapok) közti kommunikáció továbbra is probléma maradt, hiszen egyik nemzet karaktereit meg kellett feleltetni a másik nemzet karaktereinek. Az egyik nemzet kódtáblájának 178.-ik karakterét meg kellett feletetni a másik nemzet kódtáblájának egy konkrét karakterével. Pl a magyar ő betűt az angol (latin) karakter készlet valamely betűjével.
Ha az adattárházat vagy BI rendszert egyetlenegy forrásrendszerből töltenénk, akkor nem lenne probléma. Ugyanarra a kódlapra kéne tennünk az adattárházat, mint a forrásrendszert és kész.
Csakhogy nem ez a jellemző. Mi rendszerint az adattárházat több, különböző nyelvű (vagy kódlapú) adatbázisokból töltjük fel, és ebben az esetben elkerülhetetlen, hogy karaktereket az adattárház kódlapjának megfelelő karakterekké alakítsuk...
Konkrét példa
Ennyi bevezető után térjünk rá egy konkrét példára. Megpróbáltam olyat keresni, amellyel – ha még nem is találkozott - biztos, hogy előbb-utóbb találkozni fog.
Képzelje el, hogy magyar nyelvű adatokat kell áttöltenünk magyar nyelvű adatbázisba, de a két adatbázis kódlapja eltér. A forrásadatbázis collation-e Latin1 (1252-es codepage) a céladatbázis collation-e magyar (1250-es codepage). Gyakori eset ugye? Igen, hiszen az SQL Server default collation-e a Latin1. így gyakran előfordul, hogy a forrásrendszerink Latin1-es kódlapúak.
Rábízhatjuk az SQL Serverre a kódkonverziót, hiszen az képes erre, de ekkor értékes ékezeteket vesztenénk. Például a hullámos „o” betűből csinálna nekünk egy o betűt, és ennek mi nem örülnénk...
Magyar nyelvi sajátosságoknak megfelelő adattárház építése
Az első lépés amin még tervezéskor el kell gondolkodnunk az az, hogy milyen legyen a staging terület kódlapja. (A Staging terület az az adatbázis, ahová gyorsan, mindenféle átalakítás nélkül, egy az egyben betöltjük a forrásadatokat, majd innen töltjük tovább az adattárházba)
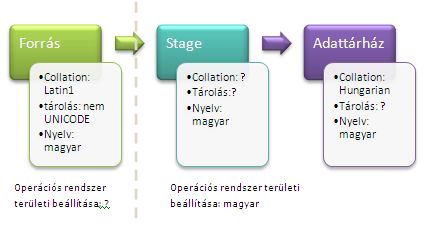
Követelmények a stage adatbázissal szenben:
- A Stage adatbázis kódlapja egyezzen meg az adattárház kódlapjával (Ennek okát lásd később)
- A Stage adatbázis tartalmazzon minden karaktert a forrásrendszerből. (Ennek oka remélem érthető)
Ezt csak úgy tudjuk elérni, ha a stage területen minden szöveget UNICODE-ként tárolunk! (A Unicode az a karakterkészlet, amely a világ összes karakterét tartalmazza. Persze nem egy bájton, mert 256 karakteren nem lehet ábrázolni a világ összes karakterét...)
Beállítjuk a STAGE adatbázis karakter típusait unicode-ra és betöltjük az az adatokat a forrásrendszerből. De ezzel még nincs megoldva a probléma, hiszen a Staging adatbázisban továbbra is azok az hullámos o-betűk vannak amelyeknek, nincs párja a magyar kódkészletben, de már birtokon belül vannak az adatok és innen kezdve már a mi kezünkben van a folyamat.
Tehát a UNICODE-os tárolással megoldjuk azt a problémát, hogy a stage területen jelenjen meg minden egyes forrásrendszeri betű, úgy ahogy az a forrásrendszerben van.
De a UNICODE-os tárolásnak van még egy óriási előnye: Nem kell továbbá foglalkozni azzal a problémával ami abból fakadhat, hogy a forrás és cél szerverek windows területi beállításai eltérhetnek egymástól. Nem beszéltem még róla, és most nem is fogok részletesen, de az, hogy mi lesz az „o” betűből nem csak attól függ, hogy milyen az adatbázis collation-e, hanem attól is, hogy milyen az operációs rendszer területi beállítása. (csak, hogy tovább bonyolódjon a probléma :-) )
Mondok egy példát: Egy angol (Latin1) nyelvi beállítású adatbázisba akarok beszúrni egy o-betűt. A latin1 karakterkészlet tartalmazza az o betűt mégsem tudom betölteni egy magyar nyelvi beállítású számítógépen.
Az
Insert into t values ('o')
utasítás eredménye „o” betűként fog bekerülni az adatbázisba, pedig a latin1 karakterkészlet tartalmazza az „o” betűt. Csakhogy az operációs rendszer magyar karakterkészlete nem.
Ahhoz, hogy ezt elkerüljük az „o” betűt UNICODE-ként kell betöltenünk:
Insert into t values (N'o')
és az „o” betűt tényleg „o” betűként fog bekerülni az adatbázisba.
Szumma szummárum Stage területen tároljunk mindent UNICODE-on! Így elkerülhetjük a Windows területi beállítások különbözőségéből származó esetleges konverziós problémákat.
Most pedig írok néhány sort a megvalósításról is, mert sajnos az sem triviális:
Az SQL Server simán megbirkózik azzal, hogy egy Latin1 kódlapú karaktert, mint például az „o” betű áttöltsön egy unicode oszlopba, de az SSIS már nem:
Columns "A" and "B" cannot convert between unicode and non-unicode string data types.
szól a hibaüzenet
Innentől kezdve két lehetőségünk van:
- A forrásoldalon alakítjuk át az adatokat UNICODE-dá (Cast as nvarchar…)
- A data flow-ban alakítjuk át az adatokat UNICODE-dá. (pl data conversion task-kal, bár ez nekem még sohasem sikerült :-) )
Tegyük fel, hogy feltölti az adattárházat, de a karakterek valahogy még sem stimmelnek. Elkezd gondolkodni, és már abban sem lesz biztos, hogy a lekérdezés azokat a karaktereket adja vissza amelyek ténylegesen le vannak tárolva. Előfordulhat ez? Igen...
tipp: Honnan tudja, hogy ténylegesen milyen karakter tárolódott az adattárházban? (Hiszen a kliens is konvertál megjelenítéskor!)
Egy select * from tábla lekérdezés eredménye egyáltalán nem biztos, hogy azt a karakterképet mutatja, ami az adatbázisban fizikailag tárolódik. Honnan tudhatjuk akkor, hogy mi tárolódott fizikailag az adatbázisban?
Lekérdezzük a karakter hexadecimális kódját:
Select Cast(oszlop as varBinary) from tábla
Ékezetes betűk betöltése a staging területről az adattárházba
Elértünk oda, hogy birtokon belül vannak az adatok, minden ékezetes karakter, úgy ahogy a forrásrendszerben volt itt csücsül a stage-en. Tele olyan „o” betűkkel, amely nem található meg a magyar karakterkészletben. A feladat tehát továbbra is adott: tovább kell tölteni az adatokat stage területről az adattárházba.
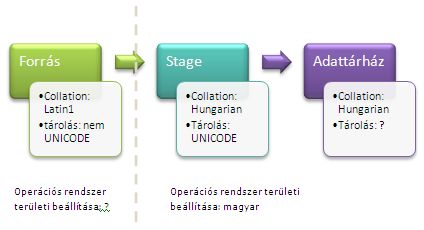
Erre az adattárház mérettől függően két lehetőségünk is van:
Ha unicode-ként tároljuk az adatokat az adattárházban, akkor nincs több problémánk: Mindenféle konverzió nélkül tölthetjük tovább az adatokat stage területről az adattárházba. Ám ebben az esetben számítanunk kell arra, hogy dimenzió tábláink mérete majdnem a duplájára fog nőni. Csak összehasonlításul: tegyük fel, hogy egy 10 millió elemű dimenziótábla kb. 5 gigát foglal. Ha ugyanezt a dimenziótáblát unicode-ként fogjuk tárolni, akkor majdnem 7-8 gigát fog foglalni a lemezen.
Ha úgy döntünk, hogy a fentiek miatt nem fogjuk UNICODE-on tárolni az adatokat, akkor a stage területről konvertálnunk kell a karaktereket.
Collate záradék.
Konvertáljunk, de ne a Collate záradék használatával! Sokszor látom, hogy a fejlesztők, ha UNICODE adatokat kell betölteni egy nem unicode adattípusba, akkor - hogy elkerüljék a „collation conflict”-et - az alábbi szintaktika szerint olvassák fel a staging adatbázis adatait:
Select oszlop Collate Hungarian_CI_AS from STAGE
Ez az amit úgy hívnak, hogy implicit konverzió és kerülni kell mint a tüzet. Mit csinál a Collate záradék az „o” betűinkkel? Megkeresi a magyar megfelelőjét és mivel nincs ezért átkonvertálja „o”-ra. Persze az adattárház felhasználó nem is tudja, hogy egy ilyen hibás implementációs lépés eredményeként elveszett néhány ékezetes betűt...
konverzió karakterről karakterre
Akár Integration Services-zel, akár tárolt eljárásokkal töltjük tovább az adatokat a staging adatbázisból az adattárházba, az ékezetes karakterek egy részét konvertálnunk kell. Ha SQL-ből konvertálunk, akkor még a stage-ről való olvasáskor át kell alakítanunk a karaktereket.
Menete:
- Átkonvertáljuk a latin karaktereket UNICODE-ra és magyar kódlapúra
- Kicseréljük a szövegben az u, U, o, Ő betűket a magyar betűkre
- Visszakonvertáljuk az így kapott sztringet unicode-ról varchar-ra
Mutatom:
SELECT
CONVERT(char(100),
replace(
CONVERT(nchar(100),[Oszlop]) collate Hungarian_CI_AS
,N'o',N'o')
)
FROM tábla
Nem szép ez az SQL utasítás! sőt jó csúnya, de legalább rendben lesznek az ékezetes betűk az adattárházban!
Összefoglalás
Vegyük számításba, hogy mitől függ az, hogy mivé alakul a forrásrendszerből betöltött hullámos o betű:
- a céladatbázis (STAGE) nyelvi beállításától (Collation)
- a céladatbázis (STAGE) adattípusától (unicode, vagy nem unicode)
- a céladatbázis operációs rendszerének területi beállításaitól (Regional Setting)
Plusz még tudnunk kell, hogy a kliens is konvertál, tehát egy lekérdezés koránt sem biztos, hogy pont ugyanazt a karaktert mutatja, mint ami a szerver adatbázisában fizikailag tárolva van...
Sok-sok kérdőjel, aluldokumentáltság, és kevés biztos pont. Ez jellemzi az adatbetöltéseket magyar nyelvi környezetben. Éppen ezért összeállítottam Önnek egy olyan referencia architektúrát, amely garantálja, hogy az ékezetek nem tűnnek el.
- Az adattárház operációs rendszerének területi beállítása legyen magyar
- Az SQL Server collation-e legyen Hungarian_Technical_CI_AS (Azaz minden adatbázis collation-e legyen Hungarian_Technical_CI_AS, ideértve az OLAP-ot is)
- Staging területen legyen minden szöveg UNICODE-ként tárolva
- Az adattárházban legyen minden UNICODE-on tárolva (10 milliós elemszámú dimenziók esetén ezt célszerű felülvizsgálni, de addig nem nagyon éri meg)
Ha mindezeket már a tervezés során figyelembe veszi, biztos lehet abban, hogy Önnek nem fognak fejfájást okozni az ékezetes betűk, és az Ön adattárházában minden karakter szépen fog megjelenni.

Kővári Attila - BI projekt




Új hozzászólás