Személyek modellezése Power BI-ban II.
A múltkori személyek modellezése Power BI-ban című cikkben megbeszéltük, hogy az azonos nevű személyek megkülönböztetésének egyik lehetséges útja Power BI-ban, ha
- a személyeket tartalmazó tábla dolgozó kód oszlopát Key Column-á tesszük Power BI-ban
- és a dolgozó név oszlop Keep Unique Rows tulajdonságát igazra állítjuk tabular editorrak
Ennek hatására a dolgozó neve és kódja mellett megjelenik egy új, belépőkártyát szimbolizáló ikon:
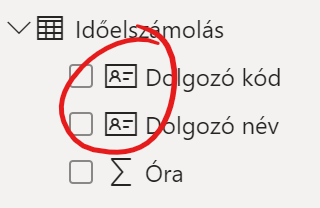
És az azonos nevű dolgozókat nem fogja összevonni a Power BI:

De hogyan valósítja ezt meg a háttérben Power BI? Úgy hogy minden dolgozó név oszlopra hivatkozó DAX lekérdezésbe belefoglalja a dolgozó kódját is. Mutatom a fenti táblázat feltöltéshez generált DAX lekérdezés releváns részét:
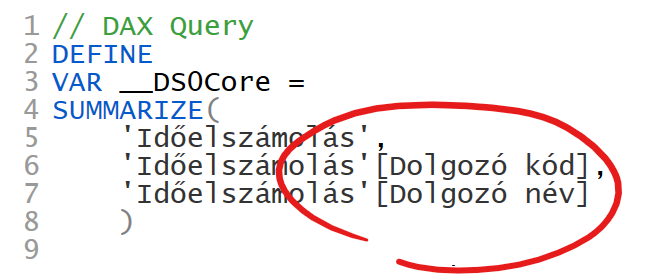
Azaz hiába csak a dolgozó nevét tartalmazza a táblázat, a táblázat feltöltéséhez használt DAX lekérdezés lekérdezi a dolgozó kódját is. A Power BI tehát úgy teszi egyedivé megjelenítéskor a dolgozó nevét, hogy hozza a kódját is, és a kettőre aggregál.
Hol üthet ez vissza?
Minden olyan measure-ben, ahol a dolgozó nevére szűrünk…
Tegyük fel, hogy dolgozók teljesítményét kell vizsgálnunk a csoportátlaghoz képest. Vagy vegyünk egy még egyszerűbb példát: dolgozók hozzájárulást szeretnénk vizsgálni a csoport teljesítményéhez. Ehhez ki kell számolnunk a csoport teljesítményét:
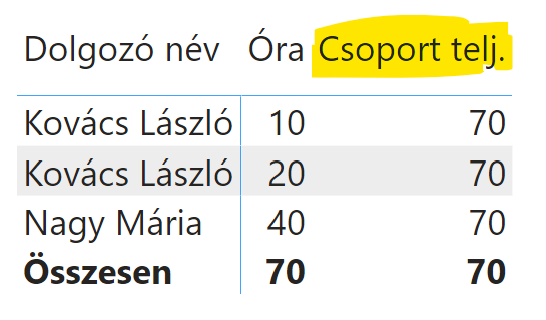
Mindenki, aki az elmúlt 10 éven Power Pivot vagy Power BI tanfolyamon járt nálam, álmából felriadva is tudja, hogy ehhez a REMOVEFILTERS() (korábban ALL()) függvényt kell használni, és rutinból megírja a képletet:

Behúzza a számított mezőt a mátrixba, és döbbenten figyeli, hogy mit ír ki a mátrix:
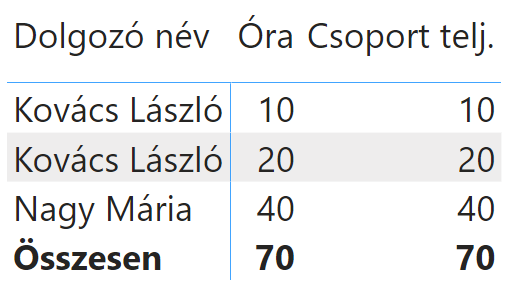
Először feljajdul, a szívéhez kap. Öngyilkos akar lenni egy töltött revolverrel, mert még egy ilyen primitív REMOVEFILTERS() függvényt sem tud használni, majd a mezőlistában megpillantja a belépőkártya ikont a dolgozó név oszlop mellett
belépőkártya ikon a dolgozó kód és név oszlop mellett
És magához tér. Eszébe jut ugyanis, hogy ebben az esetben hiába szünteti meg a szűrést a REMOVEFILTERS()-szel a dolgozó nevén, a mátrixbeli lekérdezés szűr a kód oszlopra is, és ahhoz, hogy a kívánt eredményt elérje, a kódoszlopot is bele kell foglalnia a szűrés feloldásába. Átírja a képletet:

A világbéke visszaáll. a Power BI jól számolja a csoport teljesítményét:
Ezek után már egy egyszerű osztással könnyen ki tudja számolni az egyén hozzájárulását a csoport teljesítményéhez…
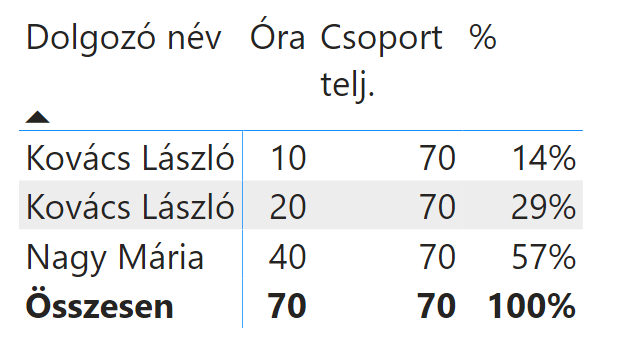
Összefoglalva: Óvatosan használja a Key Column – Keep Unique Rows párost az ismétlődő elemek megtartására, mert a háttérben a Power BI olyan DAX lekérdezést generál, amely a név oszlop mellett a kód oszlopra is hivatkozik, és ez a névre szűrő számított mezőknél nem várt eredmény okozhat…
Ha pedig nem Ön készítette a Power BI adatmodellt, és a mezőlistában egy oszlop neve mellett belépőkártya ikont lát, akkor jusson eszébe, hogy a háttérben a DAX, a „belépőkártyás” oszlopokat együtt kezeli, a vizualizációk által a Tabular modell felé küldött lekérdezések annyi sort fognak visszaadni ahány különböző eleme van a belépőkártyás (kód + név) oszlopoknak.

Kővári Attila - BI projekt
![]()
POWER BI WORKSHOP
Tudjon meg többet az itt elhangzottakról! Jöjjön el a 2026. szeptember 24.-i Power BI workshopra vagy rendeljen kihelyezett képzést! Részletek >>




Új hozzászólás