Integration Services 2008 újdonságok – Tökéletesített Data Flow taszk
In medias res, azaz vágjunk a közepébe - ahogy a magyar tanárom sulykolta belénk éveken át az Iliász kezdésével kapcsolatban - és kezdjünk rögtön az újdonság bejelentésével:
Optimalizálták a hosszú, egy execution tree-ből álló, szinkron transzformációk teljesítményét.
Első körben értelmezzük ezt a mondatot és vizsgáljuk meg, hogy mit jelentenek az „execution tree" és a „szinkron transzformáció" fogalmak. Kezdjük a szinkron transzformációkkal:
Szinkron transzformáció: Egy transzformációt szinkronnak nevezünk, ha a transzformációba belépő rekordok száma megegyezik a kilépő rekordok számával. Tipikus példája a szinkron transzformációnak, amikor egy új mezővel kiegészítjük a beérkező rekordok számát. (ugyanannyi sor jön be, mint amennyi kimegy, csak az oszlopok száma változik meg)
Szinkron transzformáció: Belépő rekordok száma = kilépő rekordok száma
Aszinkron transzformáció: Az Aszinkron transzformációk során az SSIS rész adatblokkokat olvas be a memóriába, azokból új sorokat származtat, sorokat vesz el, majd az eredményt kiírja a céltáblába. Tipikus példája a group by transzformáció.
Execution tree: Az execution tree pongyolán fogalmazva leírja azt az utat, ahogy a beérkező adatok a transzformációkon keresztül eljutnak a céljukig.
Egy execution tree-t tartalmazó SSIS csomag
Ha kiegészítettük a fenti csomagot hibakezeléssel, akkor a csomag kiegészül még egy execution tree-vel: (hiszen belép x rekord, majd kilép y+z rekord (x=y+z) ezért az SSIS egy új execution tree-t nyit meg a hibaágra érkező rekordok feldolgozására)
2 execution tree 1 DataFlow taszkon belül
Az SSIS 2005-ben minden execution tree egy szálon (work thread) futott. Ez abból a szempontból jó volt, hogy a data flow taszknak nem kellett futásidőben azzal bíbelődnie, hogy kiszámolja hány szálon kell majd futtatnia a csomagot, mekkora memóriaterületet kell majd használnia, mert azt már a csomag futásának kezdetekor, az execution tree-k száma alapján eldöntötte. De számos hátulütője is volt ennek a módszernek, hiszen az SSIS nem vizsgálta az execution tree-n belüli munka nagyságát.
Így hiába párhuzamosítottunk az execution tree- n belül, az továbbra is csak egy szálon futott és egy processzort használt! Nézzük meg a következő valós életből vett példát:
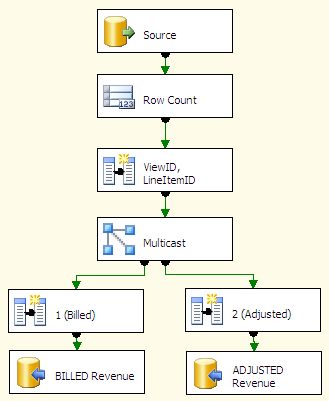
Egy data flow taszk és a komponensei
A data flow taszk nem csinál mást, mint kiolvassa egy tábla tartalmát, majd azt a multicast komponens felhasználásával „megduplázza" , néhány egyszerű transzformációt végre hajt rajta, majd az adatokat elküldi két külön táblába.
Vajon hány execution tree-ből áll ez az SSIS csomag?
Látszólag kettőből, hiszen a forrástól célig tartó útból kettő van. (Forrás - Billed Revenue tábla; Forrás - Adjusted revenue tábla) De az igazság az, hogy a fenti data flow taszk csak egy execution tree-ből áll, hiszen a Multicast taszk egy szinkron taszk, és így az SSIS nem nyit új execution tree-t: Mindent ugyanazon a szálon futtat, ugyanazt a memória területet használja. Ez pedig csak úgy lehetséges, ha sorosan futnak a komponensek:
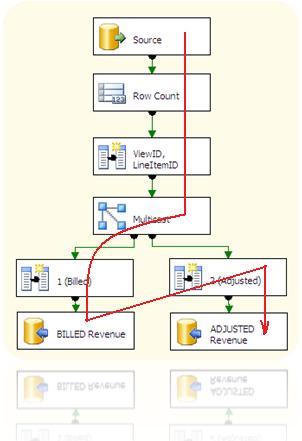
Párhuzamos komponensek soros futtatása az SSIS 2005-ben
Látható, hogy egy execution tree-n belül teljesen felesleges volt párhuzamosítanunk, hiszen az SSIS úgyis sorosan dolgozta fel a transzformációkat.
Az SSIS 2008 már képes egy execution tree-t több szálra bontani, így több processzort használni párhuzamosan. Igaz ez az egyprocesszoros gép esetén jelent némi overhead-et, de nem nagyon használnak manapság egyprocesszoros gépet az adattárházak feltöltésére :-)
A tökéletesítés eredménye
Sajnos a fentiek eredményét még nem tudtam élesben tesztelni, de találtam egy olyan Microsoftos embert, aki blogjában bemutatja a saját tesztelési eredményeit:
Az alábbi ábrák processzorok kihasználtságát mutatják ugyanazt a csomagot futtatva SSIS 2005-ön és 2008-on :
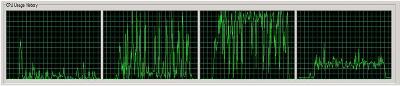
Az Integration Services 2005 processzor használata
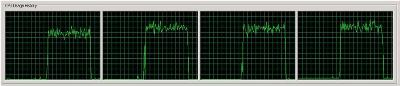
Az Integration Services 2008 processzor használata
Látható, hogy a 2008-as SSIS messze jobban kihasználja a többprocesszoros gépek teljesítményét, mint elődje tette. Az SSIS fejlesztői egyébként azt ígérik, hogy a teljesítmény javulás a szinkron komponensek párhuzamosítása eredményeképpen néhány százaléktól egészen a 2005-ös verzió feldolgozási sebességének kétszereséig nőhet. Legyen igazuk.
Felhasznált irodalom:
- Michael Entin: Katmai SSIS data flow task improvements
- Elizabeth Vitt: Integration Services: Performance Tuning Techniques
További információt úgy találhat a témában, ha rákeres a Data Flow Thread Allocation, és a pipeline parallelism kulcsszavakra az interneten.

Kővári Attila - BI projekt




Új hozzászólás