Az SSIS architektúrája és az optimalizáció lehetőségei
Ne ijedjen meg a következő ábrától, nem fogunk végig menni az architektúra komponensein, pusztán 2 fő komponensről szeretnék néhány szót ejteni:
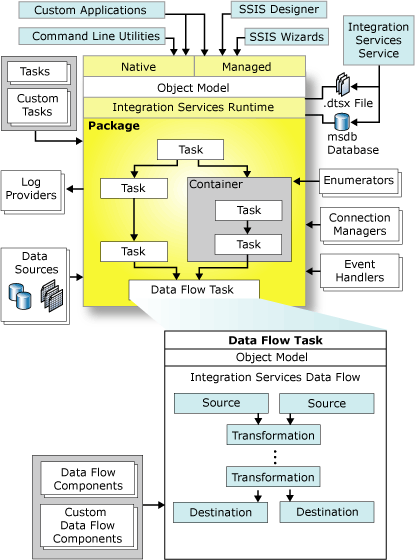
Az integration Services (SSIS) architektúra ábrája
Az Integration Servicesnek két fő alrendszere van: A Runtime engine (ez látható sárgával az ábrán) és a Data Flow engine (Ez található az ábra jobb alsó sarkában)
Run-time engine
Maga a run-time engine egy folyamatirányító alrendszer, ami azért felel, hogy az egyes feladatok a meghatározott sorrendben, a megelőző feladat futásának eredményének függvényében fussanak le. (A backup után fusson egy fájlmásolás, és ha ezek sikeresek voltak akkor szúrjunk be egy sort a naplóba)
A Run-time engine teljesítménye elsősorban olyan elemek (adatbázis szerverek, hálózatok, hardverkomponensek) teljesítményétől függ, amelyeket adottságnak tekinthetünk. Ezek teljesítményét nem nagyon tudjuk befolyásolni, így figyelmünket célszerű a másik fő alrendszer, a Data Flow Engine felé irányítanunk
Data Flow Engine
A DataFlow Engine fő feladata az adatok kiolvasása, transzformálása és beillesztése a cél adatbázisba. Ez az az alrendszer, aki az adatok adatbázison kívüli mozgatásáért felel: Szövegfájlokból, adatbázisokból kiolvassa az adatokat, beolvassa a memóriába (pufferekbe), ott valamilyen transzformációt hajt végre rajtuk, majd az eredmény visszaírja a diszkre, vagy egy másik adatbázisba.
A Data Flow engine teljesítményét - ellentétben a Run-time engine teljesítményével - már nem tekinthetjük adottságnak. A memória használat (puffer használat) optimalizálásával ugyanis jelentősen növelhetjük betöltő programjaink sebességét. Minél kevesebb memóriát használunk az adatok feldolgozásához, azaz minél kevesebb puffer szükséges a betöltési feladat megoldásához, annál hatékonyabb, gyorsabb lesz a betöltő programunk.
Transzformáció típusok: Szinkron és aszinkron transzformációk
A pufferhasználat optimalizálásához szükséges még megismerkednünk az adattranszformációk típusával. Az egyes transzformációk ugyanis eltérően hatnak a puffer használatra. Vannak olyan transzformációk amelyeket végrehajtása során a memóriába belépő és kilépő sorok száma azonos és vannak olyan transzformációk, ahol a memóriába olvasott sorok száma nem egyezik meg a memóriából kilépő sorok számával. (ilyen transzformáció például az aggregáció: A belépő sorok száma sorok száma sokkal több, mint a transzformáció után kilépő sorok száma)
A transzformáció típusok tehát alapvetően befolyásolják a memória használatot (és a párhuzamosíthatóságon keresztül a processzor használatot is, de ez egy másik téma) ezért érdemes megismerkednünk velük közelebbről is
Szinkron transzformációk
A sorszintű vagy más néven szinkron transzformációk során a transzformáció soronként (rekordonként) történik. A transzformáció során adatainkat soronként manipuláljuk, csak soron belül módosítunk és a bejövő és kimenő sorok száma megegyezik. Tipikus példája a sorszintű transzformációnak egy oszlop hozzáfűzése a forrástábla adataihoz. (Ilyen transzformáció például a mennyiség és egységár szorzataként előálló Ft oszlop, vagy az adott sor származásáról információt adó audit oszlopok hozzáfűzése az adatokhoz)
Aszinkron transzformációk
Aszinkron transzformációk esetében a belépő és kilépő sorok száma nem egyezik meg. Az aszinkron transzformációknak két fajtáját különböztetjük meg atól függően, hogy a transzformáció végrehajtásához szükség van-e az összes input adatra vagy nem.
Rész adatblokkokon végrehajtott transzformációk (aszinkron transzformáció)
Rész adatblokkokon végrehajtott transzformációk során rész adatblokkokat olvasunk be a memóriába, azokból új sorokat származtatunk, majd az eredményt kiírjuk a céltáblába. Tipikus példák a UNION, Join, merge joint transzformációk. Ezen transzformációk közös jellemzője, hogy a belépő és kilépő sorok száma nem azonos és a transzformáció végrehajtásához nem szükséges, hogy az összes input rendelkezésre álljon
Teljes adatblokkokon végrehajtott transzformációk (aszinkron transzformáció)
A teljes adatblokkokon végrehajtott transzformációk közé olyan transzformációk tartoznak, amelyek végrehajtásához minden egyes input sorra szükség van. Tipikusan ilyen transzformáció például az aggregálás és a rendezés.
Namost. Az aszinkron transzformációk során mindig legalább két puffert fog használni az Integration Services: egy input és egy output puffert. Ezzel ellentétben a szinkron transzformációkat végre tudja hajtani egy puffer segítségével is: Az input során feltöltött puffereken kívül más pufferekre nem lesz szüksége.
A pufferek méretezése
Az integration Services fix méretű pufferekkel dolgozik, melyet a DefautlMaxBufferRows, vagy a defaultBufferSize tulajdonságokon keresztül tudunk szabályozni. Egy puffer alapértelmezettként vagy 10000 soros (DefautlMaxBufferRows), vagy 10 megabájtos (defaultBufferSize). Fontos kritérium még, hogy egy sor nem kerülhet két pufferbe.
A legegyszerűbb betöltés optimalizáló módszer
Optimalizáció során legfőbb célunk, hogy minél kevesebb puffert használjunk a betöltéshez. Ezt úgy tudjuk elérni, ha minél jobban kihasználjuk a pufferekben rendelkezésre álló területet, azaz minél több adatot gyömöszölünk egy pufferbe.
Az SSIS package-ek futás előtt határozzák meg a pufferek méretét. Ha adatforrásunk ismert adatbáziskezelő, akkor az SSIS viszonylag könnyen meg fogja tudni határozni, hogy egy beolvasandó rekord memóriába töltéséhez hány bájtra van szüksége, és a rendelkezésre álló hely ismeretében azt is meg tudja határozni, hogy hány rekordot fog tudni betölteni a pufferbe.
De ha szövegfájlokkal dolgozunk és az SSIS nem tudja pontosan meghatározni az adattípusok hosszát, vagy ha az adattípusok hossza az adatbázisban nem tükrözi az adatok tényleges hosszát, akkor az Integration Services a "semminek" foglalja le a memóriát. Egy pufferbe jóval kevesebb adatot fog betölteni, mint amennyire valójában képes lenne, így sokkal lassabban fog lefutni a betöltés, mint amennyit az adatmennyiség indokolt volna. S bár az SSIS lehetőséget biztosít a packege-ek memória és processzor használatának finomhangolására, játszhatunk a pufferek méretének állítgatásával, de a legegyszerűbb és legnagyobb eredményt az adattípusok hosszának precíz meghatározása hozza.

Kővári Attila - BI projekt




hozzászólás
Anonymous
v, 07/04/2010 - 17:20
Permalink
SSIS betöltés
Új hozzászólás