Case Sensitive adattárházak problémái
A kis és a nagybetű megkülönböztetése adattárház vagy döntéstámogató rendszer oldalon nem túl szerencsés. (finoman fogalmazva) Nagyon sok hibalehetőséget hordoz magában és sok esetben a riportkészítő eszközök sem támogatják a kis és nagybetű megkülönböztetését.
Ha case sensitive (kis- és nagybetűt megkülönböztető) az adattárház, akkor az abból táplálkozó OLAP adatbázisnak, és az OLAP adatbázisból riportkészítő eszközöknek is case sensitive-nek kell lennie.
Csakhogy amíg ez az OLAP adatbázis oldalon nem gond addig a riportkészítők esetében már az. Itt van példának az Excel
Az Excel kis- és nagybetű érzékenység szempontjából egy különös faj. Különös, mert néha megkülönbözteti a kis- és nagybetűket, néha nem. Ha például OLAP adatbázist kérdezünk le vele a Pivot táblán keresztül, és az OLAP oldalon a számformátumot 'PERCENT'-ként definiáljuk, akkor a Pivot tábla nem fogja százalékos formátumban megjeleníteni az adott mutatót. Ugyanakkor a formázást 'Percent'-re állítjuk, akkor tökéletesen jól formáz a Pivot tábla.
A számformázási problémát megtanulja az ember és együtt tud vele élni. Azonban egy case sensitive adatbázisból dolgozni az Excellel szinte lehetetlen. Sem a Pivot tábla sem az Excel kocka függvényei nem birkóznak meg a kis- és nagybetűben különböző dimenzió elemekkel. Ugyanis sem a Pivot tábla, sem a kocka() függvények nem különböztetik meg a kis- és nagybetűket.
Tegyük fel hogy a forrás adatbázisunk kis- és nagybetű érzékeny (case sensitive) és van egy a1 és egy A1 nevű termékünk. Ha behúzzuk a termék dimenziót sorra, akkor az Excel kilistázza mind az a1, mind az A1 nevű terméket:
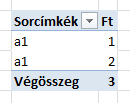
Mind a kettőt kisbetűvel. Szűrni már nem tudunk az a1 vagy az A1 termékre, mert a szűrőben vagy csupa nagybetűvel, vagy csupa kisbetűvel jeleníti meg az elemeket:


Még rosszabb a helyzet a kocka függvényekkel. A kocka függvények használatával ugyanis nem tudjuk lekérdezni mindkét elemet. A
KOCKA.ÉRTÉK("KOCKA"; "[Termék].[Összes].[a1]", [Measures].[db])
és a
KOCKA.ÉRTÉK("KOCKA"; "[Termék].[Összes].[A1]", [Measures].[db])
Ugyanazt az eredményt adja. Ergo csak az egyik elemet tudjuk lekérdezni. A másikat nem.
Mi a megoldás?
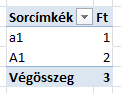
Kerülni kell döntéstámogató rendszerekben a kis- és nagybetűk megkülönböztetését :-) Ha ez nem járható és OLAP-ot használunk (Analysis Services), akkor létre kell hoznunk egy olyan származtatott oszlopot, amely nem kis és nagybetűben teszi különbözővé (egyedivé) a terméket. Pl az a1-hez hozzárendeli az 1-es kódot, az A1-hez a 2-est és erre úgy építeni egy attribútumot, hogy annak kódoszlopa az így képzet kódoszlop lesz, a megnevezés oszlopa az a1-et és A1-et tartalmazó kód. Ebben az esetben a Pivot tábla is jól fog működni, és a kocka függvények is:

Kővári Attila - BI projekt




Új hozzászólás